Spring Batch 시리즈를 포스팅하고 있습니다. 기준이 되는 버전은 5.x 버전입니다.
1. Spring Batch 소개
2. Job과 Step의 구조 및 생성
3. Job과 Step의 실행 과정
4. Job의 흐름 제어 - Flow
5. FlowJob의 실행 과정
6. 청크 기반 프로세싱의 구조 및 생성 - 현재 포스팅
7. 청크 기반 프로세싱의 진행 과정
8. Flat File, JSON 형식 파일 읽기 및 쓰기
9. DB 데이터 읽기 및 쓰기
10. Step의 예외 제어하기(스킵, 재시도)
11. 배치 작업 확장하기
지난 포스팅 까지는 `Job`과 `Step`의 컨텍스트를 중점으로 아키텍처와 기능들을 알아보았는데, 이번에는 작업의 최소 단위인 `Step` 내부의 `Tasklet` 컨텍스트를 중점으로 청크 기반 프로세싱(Chunk-oriented Processing)이 뭔지, 어떤 구조로 되어있는지, 어떻게 생성하는지 알아볼 것이다.
청크 기반 프로세싱
대량의 데이터를 일괄적으로 처리하도록 설계된 배치 작업의 특성 상, Spring Batch는 효율성과 트랜잭션 관리를 할 수 있도록 청크 기반 프로세싱 스타일을 일반적인 구현에서 사용한다.
청크 기반 프로세싱은 지정된 커밋 간격 만큼 데이터를 한 번에 하나씩 읽고, 읽은 데이터를 청크로 만들어서 트랜잭션 경계 내에서 일괄로 기록하는 것을 의미한다.
청크 기반 프로세싱을 통해 청크 단위로 커밋 및 롤백이 가능해지고, 전체 데이터가 아닌 청크 단위로 데이터를 지연해서 읽기 때문에 효율적으로 배치 작업을 수행할 수 있다. 또한 청크를 기준으로 오류를 복구하고 다시 처리할 수 있으며, 추후 청크 단위로 병렬 처리하도록 확장하여 대규모 데이터를 처리하는 데 성능을 향상시킬 수 있다.
지금까지 예시로 들었던 배치 작업들은 모두 단일 테스크 기반의 배치 작업이었다.
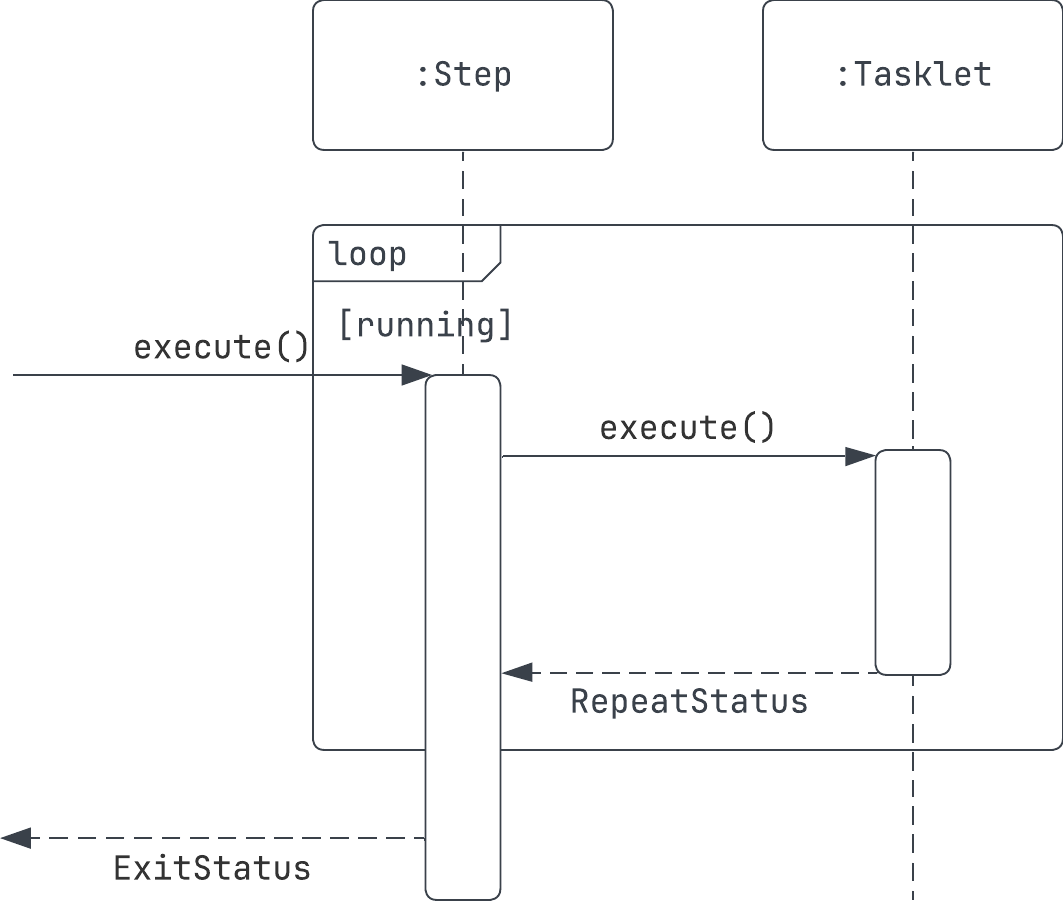
단일 테스크 기반의 배치 작업은 그냥 단순히`Tasklet` 인터페이스의 `execute` 메서드에 정의된 블록만 실행하는 게 끝이다. 반환되는 `RepeatStatus` 값에 따라서 동일한 `Tasklet`을 반복 수행하게 된다.
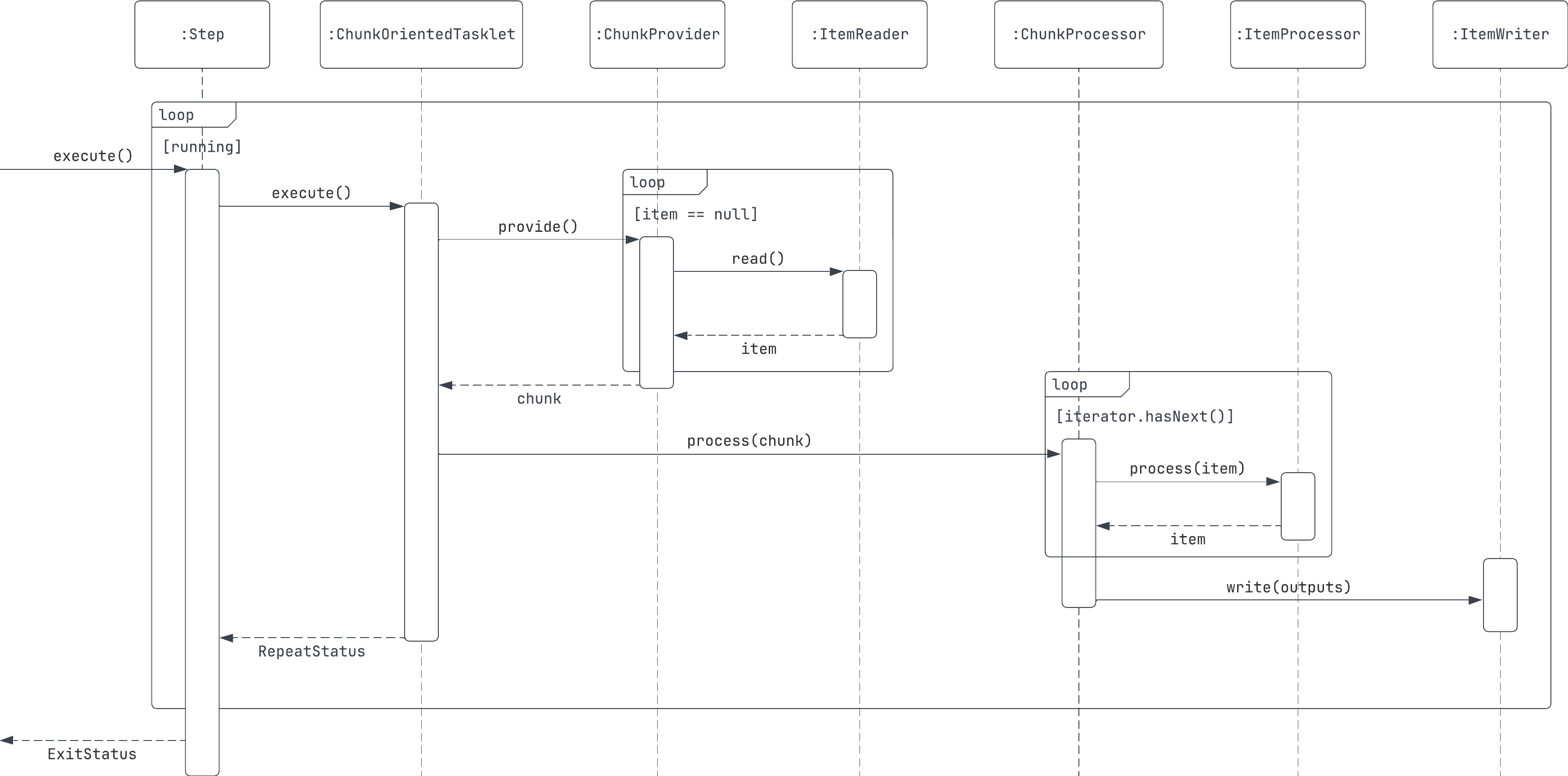
반면 청크 기반 프로세싱 기반의 배치 작업은 위와 같이 엄청 복잡하다.
`ChunkOrientedTasklet`을 통해 청크 기반 프로세싱을 진행할 수 있는데, `ChunkProvider`와 `ChunkProcessor`를 통해 데이터를 청크 단위로 읽고, 처리할 수 있다.
`ChunkProvider`는 `ItemReader`를 통해 지정된 커밋 인터벌 만큼 아이템을 읽고, 청크로 만들어 반환한다.
반환된 청크는 `ChunkProcessor`를 통해 처리되는데, `ItemProcessor`에서 청크 내 아이템을 모두 반복하여 적절한 데이터로 가공한 후, 가공된 아이템이 담겨있는 청크를 `ItemWriter`를 통해 한번에 저장하게 된다.
이제 한번 청크 기반의 배치 작업을 만들어보자.
청크 기반 배치 작업 예시
public <I, O> SimpleStepBuilder<I, O> chunk(int chunkSize, PlatformTransactionManager transactionManager) {
return new SimpleStepBuilder<I, O>(this).transactionManager(transactionManager).chunk(chunkSize);
}`StepBuilder`의 `chunk` 메서드를 통해 `SimpleStepBuilder`를 얻을 수 있는데, 이 클래스는 청크 기반 프로세싱으로 작업하는 `TaskletStep`을 빌드해주는 역할을 담당한다.
기존에 단일 테스크 기반의 작업도 `TaskletStep`을 빌드했었는데, `SimpleStepBuilder`는 `Step` 내부의 `Tasklet`을 `ChunkOrientedTasklet`으로 빌드해준다는 점이 다르다.
public class SimpleStepBuilder<I, O> extends AbstractTaskletStepBuilder<SimpleStepBuilder<I, O>> {
private ItemReader<? extends I> reader;
private ItemWriter<? super O> writer;
private ItemProcessor<? super I, ? extends O> processor;
@Override
public TaskletStep build() {
registerStepListenerAsItemListener();
registerAsStreamsAndListeners(reader, processor, writer);
return super.build();
}
public SimpleStepBuilder<I, O> reader(ItemReader<? extends I> reader) {
this.reader = reader;
return this;
}
public SimpleStepBuilder<I, O> writer(ItemWriter<? super O> writer) {
this.writer = writer;
return this;
}
public SimpleStepBuilder<I, O> processor(ItemProcessor<? super I, ? extends O> processor) {
this.processor = processor;
return this;
}
@Override
protected Tasklet createTasklet() {
Assert.state(reader != null, "ItemReader must be provided");
Assert.state(writer != null, "ItemWriter must be provided");
RepeatOperations repeatOperations = createChunkOperations();
SimpleChunkProvider<I> chunkProvider = new SimpleChunkProvider<>(getReader(), repeatOperations);
SimpleChunkProcessor<I, O> chunkProcessor = new SimpleChunkProcessor<>(getProcessor(), getWriter());
chunkProvider.setListeners(new ArrayList<>(itemListeners));
chunkProvider.setMeterRegistry(this.meterRegistry);
chunkProcessor.setListeners(new ArrayList<>(itemListeners));
chunkProcessor.setMeterRegistry(this.meterRegistry);
ChunkOrientedTasklet<I> tasklet = new ChunkOrientedTasklet<>(chunkProvider, chunkProcessor);
tasklet.setBuffering(!readerTransactionalQueue);
return tasklet;
}
}`SimpleStepBuilder`는 `StepBuilderHelper`를 상속받는 `AbstractTaskletStepBuilder`의 하위 클래스임으로, `listener`, `allowStartIfComplete`와 같은 API를 모두 사용할 수 있고, 추가로 청크 프로세싱을 위한 `reader`, `processor`, `writer` 메서드를 호출할 수 있다.
`createTasklet` 메서드는 부모의 `build` 메서드에서 호출되는데, 보면 `ChunkOrientedTasklet`을 생성하여 반환하는 것을 볼 수 있다. 이를 통해 `Step`에서 `Tasklet`의 `execute` 함수를 호출하면, `ChunkOrientedTasklet`의 `execute` 메서드가 호출되어 청크 기반의 배치 작업을 진행하게 되는 것이다.
한번 간단한 청크 프로세싱 작업을 만들어보자.
@Bean
fun job(): Job {
return JobBuilder("chunk-job", jobRepository)
.incrementer(RunIdIncrementer())
.start(chunkProcessingStep())
.build()
}
@Bean
fun chunkProcessingStep(): Step {
var index = 0
return StepBuilder("chunk-step", jobRepository)
.chunk<Int, String>(2, transactionManager)
.reader { if (++index > 6) null else index }
.processor { item -> "item: $item" }
.writer { items -> log.info(items.joinToString("/")) }
.build()
}`chunk` 메서드의 타입 파라미터로 입력(`I`)과 출력(`O`)의 대상 타입을 인자로 넣어주면 된다. 위 예시는 `Int`타입의 데이터를 읽고, `String` 타입의 데이터를 처리하는 배치 작업을 만들게 된다. 또한 메서드 파라미터로는 청크의 사이즈를 지정할 수 있는데, 2개씩 청크를 구성하도록 했다.
`reader`는 데이터를 읽는 역할을 수행하는 `ItemReader` 구현체를 인자로 넣어줄 수 있는데, 위에서 입력 타입을 `Int` 타입으로 했기 때문에 이를 반환하면 된다. `index` 값이 6이 되면 `null`을 반환하도록 구현해 놓았다.
`processor`는 입력 데이터를 받아, 출력 데이터로 변환하는 역할을 한다. 입력 데이터 타입인 `Int`형 데이터를 받아, `String`형 데이터로 변환하도록 구현해 놓았다.
`writer`는 변환된 데이터 청크를 모두 모아 한번에 쓰기 작업을 수행한다. `chunk` 메서드에서 청크 사이즈를 2로 설정했기 때문에, 2개씩 처리된다. 청크를 합쳐서 출력하도록 구현해 놓았다.

결과를 보면 2개씩 처리가 된 것을 볼 수 있다.
청크 기반 배치 작업이 어떤식으로 구성되는지 간단하게 알아보았으니, 실제 구현하게 되는 `ItemReader`, `ItemProcessor`, `ItemWriter`에 대해서 알아보자.
ItemReader
`ItemReader`는 청크 기반 프로세스에서 아이템 한건을 읽는 역할을 수행한다. `ItemReader`를 통해 읽힌 아이템은, 청크 사이즈만큼 모여 하나의 청크를 이루게 된다.
@FunctionalInterface
public interface ItemReader<T> {
@Nullable
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
`read` 메서드 하나만 가지고 있는 SAM 인터페이스이다. 타입파라미터 `T` 타입의 데이터 단건을 반환한다. 여기서 `T`는 `StepBuilder`의 `chunk` 메서드의 타입 파라미터 `I`의 인자로 주어진 타입이 들어간다.
Spring Batch에서는 다양한 소스로 부터 입력 데이터를 처리할 수 있도록 `KafkaItemReader`, `JdbcBatchItemReader` 등의 다양한 `ItemReader` 구현체들을 기본적으로 제공한다. 추후에 `ItemReader` 기본 구현체들에 대해서 모아서 다룰 것이다.
ItemProcessor
`ItemProcessor`는 청크 내의 아이템을 하나씩 처리하는 역할을 한다. 주로 읽은 아이템을 다른 타입의 아이템으로 변환하는 역할로 사용한다.
@FunctionalInterface
public interface ItemProcessor<I, O> {
@Nullable
O process(@NonNull I item) throws Exception;
}`process` 메서드 하나만 가지고 있는 SAM 인터페이스이다. 타입파라미터 `I` 타입의 데이터 단건을 받아, `O` 타입으로 반환한다. `StepBuilder`의 `chunk` 메서드의 타입파라미터 `I`, `O`와 대응된다.
`ItemProcessor`는 `ItemReader`, `ItemWriter`와 달리 필수가 아니다. 입력 데이터에 특정 처리가 필요한 경우에만 구현하면 된다. 확인을 위해 `SimpleStepBuilder`를 봐보자.
@Override
protected Tasklet createTasklet() {
Assert.state(reader != null, "ItemReader must be provided");
Assert.state(writer != null, "ItemWriter must be provided");
RepeatOperations repeatOperations = createChunkOperations();
SimpleChunkProvider<I> chunkProvider = new SimpleChunkProvider<>(getReader(), repeatOperations);
SimpleChunkProcessor<I, O> chunkProcessor = new SimpleChunkProcessor<>(getProcessor(), getWriter());
chunkProvider.setListeners(new ArrayList<>(itemListeners));
chunkProvider.setMeterRegistry(this.meterRegistry);
chunkProcessor.setListeners(new ArrayList<>(itemListeners));
chunkProcessor.setMeterRegistry(this.meterRegistry);
ChunkOrientedTasklet<I> tasklet = new ChunkOrientedTasklet<>(chunkProvider, chunkProcessor);
tasklet.setBuffering(!readerTransactionalQueue);
return tasklet;
}`reader`, `writer`는 `Assert`를 통해 필수로 제공되어야 함을 알 수 있다.
ItemWriter
`ItermWriter`는 청크를 단위로 쓰기 작업을 수행하는 역할을 한다.
@FunctionalInterface
public interface ItemWriter<T> {
void write(@NonNull Chunk<? extends T> chunk) throws Exception;
}`write` 메서드 하나만 가지고 있는 SAM 인터페이스이다. 타입파라미터 `T` 타입의 데이터 단건을 인자로 받는다. 여기서 `T`는 `StepBuilder`의 `chunk` 메서드의 타입 파라미터 `O`의 인자로 주어진 타입이 들어간다.
`ItemWriter`는 `ItemReader`와 마찬가지로, 다양한 소스로 데이터를 출력할 수 있도록 `KafkaItemWriter`, `JdbcBatchItemWriter` 등의 다양한 구현체들을 Spring Batch에서 제공한다. 대개 `ItemReader` 구현체들과 쌍을 이뤄 구현되어 있다.
ItemStream
이전에 `Job`과 `Step`의 실행 과정을 다룬 포스팅에서, `AbstractStep`의 `open`, `close` 메서드가 호출되는 부분에 `ItemStream`이 연관되어 있다고 말했었다. `Step`을 실행하기 전과 후에 처리되어야 할 행위들을 추가할 수 있도록 만들어진 확장 포인트라고 했는데, `ItemStream`에서 이를 처리하게 된다.
public interface ItemStream {
default void open(ExecutionContext executionContext) throws ItemStreamException {
}
default void update(ExecutionContext executionContext) throws ItemStreamException {
}
default void close() throws ItemStreamException {
}
}`open`, `update`, `close` 메서드가 정의되어 있으며, `open`, `close`는 `Step` 구현체가 `TaskletStep`일 경우에만 `ItemStream`의 `open`, `close`를 호출하도록 구현되어 있다.
public class TaskletStep extends AbstractStep {
@Override
protected void close(ExecutionContext ctx) throws Exception {
stream.close();
}
@Override
protected void open(ExecutionContext ctx) throws Exception {
stream.open(ctx);
}
}
`update`는 바로 다음 포스팅에서 알아볼, `TaskletStep`의 `doExecute`함수에서 호출되는 메서드이다.
근데 갑자기 왜 갑자기 `ItemStream`을 알아보는 것일까? `ItemReader`, `ItemProcessor`, `ItemWriter`와 연관이 있기 때문이다.
우선 `Step`에 `ItemStream`을 초기화하는 가장 간단한 방법은 `stream` 메서드를 호출하는 것이다.
public B stream(ItemStream stream) {
streams.add(stream);
return self();
}`AbstractTaskletStepBuilder` 클래스에 정의되어 있는 메서드이며, `Set<ItemStream>`타입의 멤버 `streams`에 추가해준다. 이 멤버는 추후 `build` 함수 호출 시, `TaskletStep`의 `setStreams` 메서드를 호출하여 모든 요소를 `Step`의 `stream`에 추가해주게 된다.
public class TaskletStep extends AbstractStep {
private final CompositeItemStream stream = new CompositeItemStream();
public void setStreams(ItemStream[] streams) {
for (ItemStream itemStream : streams) {
registerStream(itemStream);
}
}
}
`TaskletStep`의 경우에는 `CompositeItemStream` 타입의 `stream` 멤버를 가지고 있으며, 클래스명으로 부터 유추할 수 있듯, 여러 `ItemStream` 구현체들을 위임 객체로 가지고 있으며, 실행을 이 객체들에게 위임하는 클래스이다. 따라서 `ItemStream`을 여러 개 등록할 수 있다.
두 번째로 `ItemStream`을 등록하는 방법은, `ItemReader`, `ItemProcessor`, `ItemWriter` 구현체를 만들 때, `ItemStream`도 구현하는 것이다.
class CustomItemReader(): ItemReader<String>, ItemStream {
override fun read(): String? {
TODO("Not yet implemented")
}
override fun open(executionContext: ExecutionContext) {
super.open(executionContext)
}
override fun update(executionContext: ExecutionContext) {
super.update(executionContext)
}
override fun close() {
super.close()
}
}위와 같이 두 인터페이스를 한번에 구현한 후, `reader`, `processor`, `writer`로 등록하면 자동으로 `TaskletStep`의 `CompositeItemStream`의 위임객체들에 추가된다. 이렇게 되는 이유는 바로 `SimpleStepBuilder`의 `build` 메서드에 있다.
@Override
public TaskletStep build() {
registerStepListenerAsItemListener();
registerAsStreamsAndListeners(reader, processor, writer);
return super.build();
}
protected void registerAsStreamsAndListeners(ItemReader<? extends I> itemReader,
ItemProcessor<? super I, ? extends O> itemProcessor, ItemWriter<? super O> itemWriter) {
for (Object itemHandler : new Object[] { itemReader, itemWriter, itemProcessor }) {
if (itemHandler instanceof ItemStream) {
stream((ItemStream) itemHandler);
}
if (StepListenerFactoryBean.isListener(itemHandler)) {
StepListener listener = StepListenerFactoryBean.getListener(itemHandler);
if (listener instanceof StepExecutionListener) {
listener((StepExecutionListener) listener);
}
if (listener instanceof ChunkListener) {
listener((ChunkListener) listener);
}
if (listener instanceof ItemReadListener<?> || listener instanceof ItemProcessListener<?, ?>
|| listener instanceof ItemWriteListener<?>) {
itemListeners.add(listener);
}
}
}
}보면 `registerAsStreamsAndListerners` 메서드를 호출하는데, 이 메서드에서 `itemReader`, `itemWriter`, `itemProcessor` 중 `ItemStream`의 구현체를 걸러 `stream` 메서드를 통해 `streams` 멤버에 추가해주고 있는 것을 볼 수 있다.
따라서 최종적으로 부모인 `AbstractTaskletStepBuilder`의 `build` 함수에서 `TaskletStep`을 만들 때 `CompositeItemStream` 멤버의 위임 객체들로 추가되게 되는 것이다.
Spring Batch에서 이렇게 설계한 이유는, `AbstractStep`에 정의된 `open`과 `close`메서드를 리소스를 열고 닫는 확장 포인트로 정의했기 때문이다.
DB로 예를 들면, 커넥션을 열고 닫는다던지 등의 리소스 관련 작업들은 입력과 출력 데이터를 처리하기 위해 사전에 수행되어야 하는 작업들인 경우가 많다.
따라서 입출력 데이터들에 대한 읽기, 처리, 쓰기 로직이 구현되어 있는 `ItemReader`, `ItemWriter`, `ItemProcessor`에 리소스 관련 로직도 한번에 모아놓게 하기 위해서 위와 같이 구현이 되어 있는 것이다.
public interface ItemStreamReader<T> extends ItemStream, ItemReader<T> {
}
public interface ItemStreamWriter<T> extends ItemStream, ItemWriter<T> {
}위와 같이 Spring Batch에서는 두 개의 인터페이스를 구현한 편의 인터페이스도 제공하고 있다. 보통 입출력 작업이 시작되기 전에 리소스와 관련된 작업을 수행해야 하는 기본 구현체들의 경우, 위 두 인터페이스를 구현하는 경우가 많다.
StepListener
이전에 `Step`의 생성을 다룰 때, `StepExecutionListener`에 대해서 잠깐 설명했었다. (포스팅 참고) `Step`의 실행 전 후로 콜백을 제공하는 인터페이스였는데, 사실 이 `StepExecutionListener`는 `StepListener`의 구현체이며, Spring Batch에서는 여러 시점에서의 콜백을 제공하기 위해 `StepExecutionListener`를 포함하여 여러 `StepListener` 하위 구현체들을 만들어 놓았다.
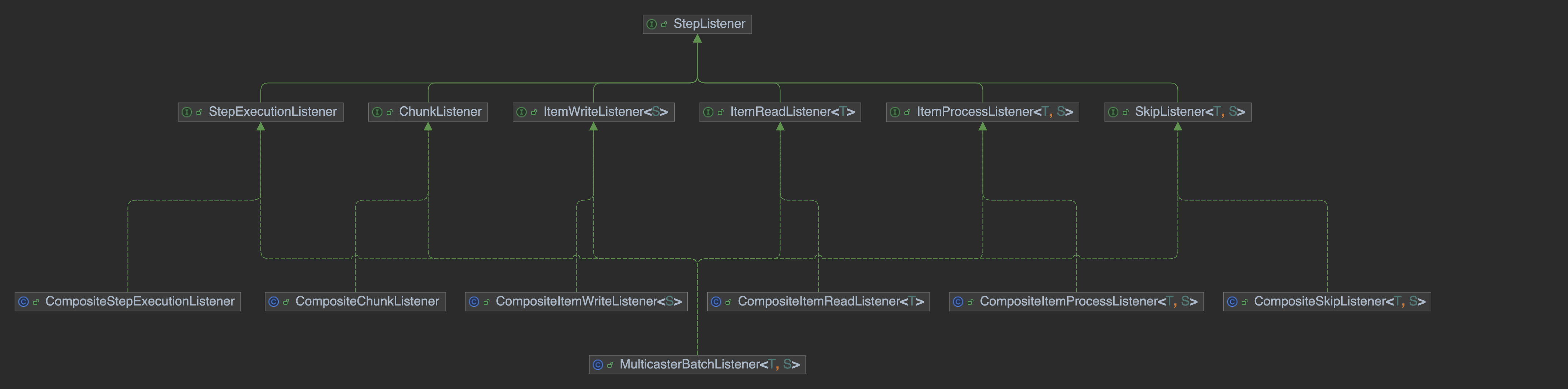
하위 구현들을 좀 단순화 하여 다이어그램으로 나타냈다. 보면 `Step`의 실행, 아이템을 읽는, 아이템을 처리하는 등등의 각 시점에 따른 `StepListener`가 구현 인터페이스가 정의되어 있다.
그리고 여러 리스너에게 위임하기 위해, 각 구현마다 컴포지트 클래스들이 구현되어 있으며, 모든 구현을 한번에 모아서 처리하기 위해 `MulticasterBatchListener`가 구현되어 있는 구조이다.
즉, 컴포지트 클래스들은 각 시점에만 한정하여 콜백을 처리하기 위해 여러 리스너 구현체들에게 위임하는 역할을 수행하고, `MulticasterBatchListener`는 모든 시점에서 콜백을 처리하기 위해 구현되어 있는 구조이다.
위와 같은 구조로 되어있는 건, 배치 작업을 담당하는 클래스 별로 적합한 `StepListener` 객체를 의존하기 위해서이다.
실제 `Step`의 실행이 시작되는 `AbstractStep`의 경우, `Step`의 실행 전후로 실행해야할 콜백이 정의된 `CompositeStepExecutionListener`만 의존하고 있다.
반면 청크 기반 작업을 처리하는 `TaskletStep`의 경우 청크 생성 직후로 실행해야 할 콜백이 정의된 `CompositeChunkListener`를 멤버로 가져 의존하고 있다.
그리고 청크를 제공하기 위해 아이템을 처리하는 `ChunkProvider`, `ChunkProcessor`에는 아이템을 읽고, 처리하고, 쓰는 직후로 실행해야할 콜백들이 대부분 필요하기 때문에 `MulticasterBatchListener`를 멤버로 가져 의존하고 있다.
즉, 각 클래스 별로 담당하는 역할에 따라 적합한 `StepListener` 객체를 의존하기 위해 여러 각 시점 별로 `StepListener` 인터페이스가 정의되어 있는 것이다.
예전에 보았듯이 `StepListener`는 `StepBuilder`의 `listener` 메서드를 통해 설정할 수 있는데, 여러 `StepBuilder`마다 설정 가능한 `StepListener`의 구현체에 따라 `listener` 메서드가 오버로딩 되어 있다.

위처럼 청크 기반 배치 작업을 생성하기 위해 `SimpleStepBuilder`를 사용한다면, 그에 따라 설정 가능한 `ItemProcessListener`, `ItemReadListener` 등등이 오버로딩 되어 있는 형식인 것이다.
그렇다면 갑자기 왜 `StepListener`에 대해서 다룰까? 이것도 `ItemStream`과 같은 이유이다.
`SimpleStepBuilder`의 `registerAsStreamsAndListerners` 메서드에서는, `ItemReader`, `ItemProcessor`, `ItemWriter`가 `ItemStream`을 구현하고 있는 경우에 `streams`에 등록이 되었는데, `StepListener`도 마찬가자이다.
if (StepListenerFactoryBean.isListener(itemHandler)) {
StepListener listener = StepListenerFactoryBean.getListener(itemHandler);
if (listener instanceof StepExecutionListener) {
listener((StepExecutionListener) listener);
}
if (listener instanceof ChunkListener) {
listener((ChunkListener) listener);
}
if (listener instanceof ItemReadListener<?> || listener instanceof ItemProcessListener<?, ?>
|| listener instanceof ItemWriteListener<?>) {
itemListeners.add(listener);
}
}`StepListener` 타입이라면, 각 구현체에 따라 형변환 후 오버로딩 된 메서드 중 적합한 메서드를 호출하여 리스너를 설정하고 있는 걸 확인할 수 있다.
따라서 정리하자면, `ItemReader`, `ItemProcessor`, `ItemWriter`에 아이템을 읽고, 처리하고, 쓰는 각 시점별로 콜백이 필요하다면 `StepListener`를 추가로 구현하면 된다.
정리
이번 포스팅에서는 청크 기반 프로세싱이 무엇인지, 어떻게 만들 수 있는지에 대해 간단하게 알아보았다.
청크 기반의 작업을 구성하는 방법은 `ItemReader`, `ItemProcessor`, `ItemWriter`를 구현하여 `SimpleStepBuilder`를 통해 `TaskletStep`을 만들기만 하면 끝이다. 그러면 해당 `TaskletStep`의 멤버 `tasklet`에 `ChunkOrientedTasklet`을 빌드해 초기화 시켜준다.
`ItemStream`에 대해서도 알아보았다. 입출력 데이터를 처리하기 위해 필요한 리소스 관련 작업들을 구현하면 되고, 보통 `ItemReader`, `ItemProcessor`, `ItemWriter`의 구현체에 같이 구현한다는 사실도 알아보았다.
`StepListener`에 대해서도 알아보았다. `ItemStream` 처럼 `ItemReader`, `ItemProcessor`, `ItemWriter`의 구현체에 같이 구현하면 되고, 각 시점에 적합한 콜백을 제공하면 된다.
다음 포스팅에서는 실제 청크 기반 프로세싱이 어떻게 진행되는지 `ChunkOrientedTasklet`부터 시작해서 과정을 상세하게 알아보자.