Spring Batch 시리즈를 포스팅하고 있습니다. 기준이 되는 버전은 5.x 버전입니다.
1. Spring Batch 소개
2. Job과 Step의 구조 및 생성
3. Job과 Step의 실행 과정
4. Job의 흐름 제어 - Flow
5. FlowJob의 실행 과정
6. 청크 기반 프로세싱의 구조 및 생성
7. 청크 기반 프로세싱의 진행 과정 - 현재 포스팅
8. Flat File, JSON 형식 파일 읽기 및 쓰기
9. DB 데이터 읽기 및 쓰기
10. Step의 예외 제어하기(스킵, 재시도)
11. 배치 작업 확장하기
이번 포스팅에서는 청크 기반 프로세싱을 수행하는 `ChunkOrientedTasklet`의 구현을 상세하게 알아볼 것이다.
`ChunkOrientedTasklet`은 `Tasklet`의 구현체이기 때문에, `TaskletStep`을 통해 실행되며, `TaskletStep`에 대해 아직 다룬 적이 없기 때문에 어떤식으로 동작하여 `Tasklet`을 실행시키는 건지 우선 알아보고, `ChunkOrientedTasklet`, `ChunkProvider`, `ChunkProcessor`의 구현을 한번 살펴보도록 하자.

들어가기 전에, 위의 청크 기반 프로세싱의 시퀀스 다이어그램을 한번 더 상기시키고 가면 이해에 도움이 될 것이다. 진행 순서도 핵심이지만, 외부의 루프와 내부의 루프가 있다는 것도 알아두면 좋다.
Tasklet 실행 과정
이전에 `SimpleStepHandler`에서 `AbstractStep`의 `execute`를 호출하면, 실제 `Step` 구현체의 `doExecute`를 호출한다고 했었다. (포스팅 참고) 따라서 이번에는 `TakletStep`의 `doExecute` 메서드를 살펴보며, 이 구현체에서 어떤 과정을 거쳐 `Tasklet`을 실행시키는지 알아보자.
TaskletStep
public class TaskletStep extends AbstractStep {
private RepeatOperations stepOperations = new RepeatTemplate();
private final CompositeChunkListener chunkListener = new CompositeChunkListener();
private final CompositeItemStream stream = new CompositeItemStream();
private PlatformTransactionManager transactionManager;
private Tasklet tasklet;
@Override
protected void doExecute(StepExecution stepExecution) throws Exception {
stream.update(stepExecution.getExecutionContext());
getJobRepository().updateExecutionContext(stepExecution);
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {
@Override
public RepeatStatus doInChunkContext(RepeatContext repeatContext, ChunkContext chunkContext)
throws Exception {
StepExecution stepExecution = chunkContext.getStepContext().getStepExecution();
RepeatStatus result;
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}
catch (UncheckedTransactionException e) {
throw (Exception) e.getCause();
}
chunkListener.afterChunk(chunkContext);
return result == null ? RepeatStatus.FINISHED : result;
}
});
}
}`doExecute` 메서드의 핵심은, `stepOprations.iterate` 이다. 이게 바로 `RepeatStatus`에 따라 `Tasklet`을 반복 실행시키는 역할을 담당한다.
실제 `stepOperations`에 초기화 된 객체는 `RepeatTemplate` 객체인데, `RepeatTemplate`는 `Tasklet`을 반복 실행시키고, 실행 중 발생한 예외에 대해서 처리하고, 반복될 때마다 실행해야 할 콜백들을 `RepeatListener`를 통해 제공할 수 있도록 설계된 클래스이다.
이번에는 `Tasklet`을 어떻게 반복 처리하는 지에 대해서만 한정하여 구현을 보도록 하자.
public class RepeatTemplate implements RepeatOperations {
@Override
public RepeatStatus iterate(RepeatCallback callback) {
RepeatContext outer = RepeatSynchronizationManager.getContext();
RepeatStatus result = RepeatStatus.CONTINUABLE;
try {
result = executeInternal(callback);
}
return result;
}
private RepeatStatus executeInternal(final RepeatCallback callback) {
RepeatStatus result = RepeatStatus.CONTINUABLE;
try {
while (running) {
if (running) {
try {
result = getNextResult(context, callback, state);
}
if (isComplete(context, result) || isMarkedComplete(context) || !deferred.isEmpty()) {
running = false;
}
}
}
result = result.and(waitForResults(state));
}
return result;
}
protected RepeatStatus getNextResult(RepeatContext context, RepeatCallback callback, RepeatInternalState state)
throws Throwable {
return callback.doInIteration(context);
}
protected boolean isComplete(RepeatContext context, RepeatStatus result) {
boolean complete = completionPolicy.isComplete(context, result);
if (complete) {
logger.debug("Repeat is complete according to policy and result value.");
}
return complete;
}
}
`iterate` 함수는 `RepeatCallback`을 인자로 받아, `executeInternal` 메서드로 보낸다. 그리고 `executeInternal` 메서드에서는 `running`이 `true`인 경우 계속 반복하여 `getNextResult` 메서드를 호출하게 된다.
`running`이 `false`가 되는 경우는 주로 `isComplete` 메서드를 통해 확인하는데, `CompletionPolicy`를 통해 완료 상태인지 확인한다. 초기화 된 구현체는 `DefaultResultCompletionPolicy`이며, 이 구현체는 단순히 `Tasklet`이 실행된 후 반환되는 `RepeatStatus`가 `CONTINUABLE`인 경우 `true`를 응답한다.
`getNextResult` 메서드는 인자로 넘어온 `RepeatCallback`의 `doInIteration` 메서드를 호출하게 되는데, 여기서 인자로 넘어오는 `RepeatCallback`은 `TaskletStep`의 `doExecute` 메서드에서 `iterate`를 호출할 때 구현한 `StepContextRepeatCallback`의 익명 클래스 인스턴스가 들어가 있게 된다. 다시 `TaskletStep`의 코드를 봐보자.
stepOperations.iterate(new StepContextRepeatCallback(stepExecution) {
@Override
public RepeatStatus doInChunkContext(RepeatContext repeatContext, ChunkContext chunkContext)
throws Exception {
StepExecution stepExecution = chunkContext.getStepContext().getStepExecution();
interruptionPolicy.checkInterrupted(stepExecution);
RepeatStatus result;
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}
chunkListener.afterChunk(chunkContext);
return result == null ? RepeatStatus.FINISHED : result;
}
});보면 `StepContextRepeatCallback`을 익명 클래스로 구현하여, `doInChunkContext` 메서드만 오버라이딩 했다. 이 `doInChunkContext` 함수는 `doInIteration` 메서드에서 호출된다. 한번 `StepContextRepeatCallback`의 구현을 살펴보자.
public abstract class StepContextRepeatCallback implements RepeatCallback {
private final StepExecution stepExecution;
@Override
public RepeatStatus doInIteration(RepeatContext context) throws Exception {
try {
return doInChunkContext(context, chunkContext);
}
}
}코드가 많이 생략되어 있긴 하다만.. 아무튼 `doInChunkContext`를 호출한다는 점을 확인할 수 있다.
지금까지 핵심만 정리해보자면, `Tasklet`을 반복시키는 것은 `RepeatOperation`의 `iterate`가 담당하고 있고, 결론적으로는 익명 클래스에 구현된 `doInChunkContext` 메서드를 반복적으로 수행한다는 점이다.
그리고 다시 이어서, 실제 `Tasklet`을 호출하는 부분은 `TransactionTemplate`의 `execute` 함수라는 점이다.
try {
result = new TransactionTemplate(transactionManager, transactionAttribute)
.execute(new ChunkTransactionCallback(chunkContext, semaphore));
}`doInChunkContext` 구현부를 보면, `TransactionTemplate` 인스턴스를 만들어서 `execute`함수를 호출하는 것을 볼 수 있다.
`TransactionTemplate` 클래스는 트랜잭션 경계를 설정하고, 작업이 종료되면 커밋을, 작업 중 예외가 발생하면 롤백을 처리하는 클래스이다. `TransactionTemplate`의 `execute` 함수를 한번 살펴보자.
@Override
@Nullable
public <T> T execute(TransactionCallback<T> action) throws TransactionException {
else {
TransactionStatus status = this.transactionManager.getTransaction(this);
T result;
try {
result = action.doInTransaction(status);
}
catch (RuntimeException | Error ex) {
rollbackOnException(status, ex);
throw ex;
}
catch (Throwable ex) {
rollbackOnException(status, ex);
throw new UndeclaredThrowableException(ex, "TransactionCallback threw undeclared checked exception");
}
this.transactionManager.commit(status);
return result;
}
}보면 인자로 넘어온 `TransactionCallback`의 `doInTransaction`을 실행하기 전에 트랜잭션을 얻고, 중간에 예외가 발생하면 롤백을, 아니라면 커밋을 처리하는 것을 볼 수 있다.
인자로 넘어오는 `TransactionCallback`은 `TaskletStep` 내부 클래스로 정의된 `ChunkTransactionCallback` 클래스의 인스턴스이다. 이 인스턴스의 `doInTransaction`이 호출되며, 여기서 실제 `tasklet`의 `execute`가 호출되게 된다.
정리

글로만 설명을 하니.. 너무 복잡하고 흐름이 이해가 안갈 거 같다. 지금까지 설명한 부분은 위 시퀀스 다이어그램의 파란색으로 칠해진 부분, 즉 `Step`에서 `ChunkOrientedTasklet`을 실행시키는 과정 까지 설명한 것이다.
하나하나 모두 기억할 필요는 없고, 이 부분에서는 `Step`에서 `Tasklet`의 `execute`를 호출하기까지의 과정과, 어떻게 반복을 처리하는 지에 대해서, 그리고 트랜잭션을 언제 얻어서 커밋과 롤백이 이루어지는지에 대해서만 기억을 해두면 될 거 같다.
이를 청크 기반 프로세싱에 접목해서 정리를 하자면, 하나의 청크를 기준으로 반복을 처리하게 되고, 하나의 청크를 기준으로 트랜잭션의 커밋과 롤백이 이루어진다고만 알고 있으면 될 거 같다.
ChunkOrientedTasklet 진행 과정
이전까지 `Tasklet`의 `execute`가 호출되기 까지의 과정을 보았다. 이제 그럼 실제 `ChunkOrientedTasklet`의 `execute`부터 시작해서 어떻게 청크 기반 프로세싱이 진행되는지 살펴보자.
ChunkOrientedTasklet
public class ChunkOrientedTasklet<I> implements Tasklet {
private final ChunkProcessor<I> chunkProcessor;
private final ChunkProvider<I> chunkProvider;
public ChunkOrientedTasklet(ChunkProvider<I> chunkProvider, ChunkProcessor<I> chunkProcessor) {
this.chunkProvider = chunkProvider;
this.chunkProcessor = chunkProcessor;
}
@Nullable
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
@SuppressWarnings("unchecked")
Chunk<I> inputs = (Chunk<I>) chunkContext.getAttribute(INPUTS_KEY);
if (inputs == null) {
inputs = chunkProvider.provide(contribution);
if (buffering) {
chunkContext.setAttribute(INPUTS_KEY, inputs);
}
}
chunkProcessor.process(contribution, inputs);
chunkProvider.postProcess(contribution, inputs);
chunkContext.removeAttribute(INPUTS_KEY);
chunkContext.setComplete();
return RepeatStatus.continueIf(!inputs.isEnd());
}
}구현 자체는 간단하다. `ChunkProvider`의 `provide`를 통해 `Chunk`를 얻어온 후, 해당 청크를 `ChunkProcessor`의 `process` 메서드의 인자로 넘겨주어 처리한다.
그리고 만약 청크가 마지막이 아닌 경우, `RepeatStatus`를 `CONTINUABLE`로 반환하여 `TaskletStep`의 `RepeatOperations`에서 `Tasklet`을 반복 실행시키게 된다.
SimpleChunkProvider
`ChunkOrientedTasklet`에서 `provide`를 호출하면, `SimpleChunkProvider`의 `provider`가 호출된다.
public class SimpleChunkProvider<I> implements ChunkProvider<I> {
protected final ItemReader<? extends I> itemReader;
private final MulticasterBatchListener<I, ?> listener = new MulticasterBatchListener<>();
private final RepeatOperations repeatOperations;
@Nullable
protected final I doRead() throws Exception {
try {
listener.beforeRead();
I item = itemReader.read();
if (item != null) {
listener.afterRead(item);
}
return item;
}
catch (Exception e) {
listener.onReadError(e);
throw e;
}
}
@Override
public Chunk<I> provide(final StepContribution contribution) throws Exception {
final Chunk<I> inputs = new Chunk<>();
repeatOperations.iterate(context -> {
I item;
Timer.Sample sample = Timer.start(Metrics.globalRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
item = read(contribution, inputs);
}
catch (SkipOverflowException e) {
status = BatchMetrics.STATUS_FAILURE;
return RepeatStatus.FINISHED;
}
finally {
stopTimer(sample, contribution.getStepExecution(), status);
}
if (item == null) {
inputs.setEnd();
return RepeatStatus.FINISHED;
}
inputs.add(item);
contribution.incrementReadCount();
return RepeatStatus.CONTINUABLE;
});
return inputs;
}
}
`provide` 메서드를 보면, `TaskletStep`이 반복해서 `Tasklet`을 실행시키는 것처럼 `repeatOperations`를 통해 아이템을 반복해서 읽고 있다.
여기서도 마찬가지로 `RepeatTemplate` 객체가 초기화 되어 있는데, `running`을 `false`로 만드는, `CompletionPolicy` 객체가 다르다. `TaskletStep`의 `RepeatTemplate` 인스턴스에는 `DefaultResultCompletionPolicy` 객체가 초기화 되어있었지만, 여기에는 `SimpleCompletionPolicy` 객체가 초기화 되어 있다.
`SimpleCompletionPolicy`는 `DefaultResultCompletionPolicy`를 상속받는 하위 클래스로, `RepeatContext`에 저장된 `count`가 청크의 사이즈보다 크거나 같아진다면 `isComplete`가 `true`가 된다.
그냥 단순하게 말하면, 청크 기반 `Step`을 생성할 때 인자로 주었던 `chunkSize`만큼 데이터를 읽었다면 완료 처리를 하여 그 이후의 데이터를 읽지 않도록, 반복을 종료시키는 역할을 하는 것이다.
아이템을 읽는 `doRead` 함수는 `MulticasterBatchListener`를 통해 읽기 전, 후와 예외가 발생할 경우 실행해야 할 콜백을 실행하고 아이템을 반환한다. `MulticasterBatchListener`와 관련된 내용은 이 포스팅을 참고하길 바란다.
그렇게 반환된 아이템을 `inputs` 에 추가한 후, 반복이 종료되면 `inputs`를 반환하게 되는 것이다.

방금 다룬 과정은 시퀀스 다이어그램의 파란 배경 부분에 해당한다.
SimpleChunkProcessor
`SimpeChunkProvider`에서 반환된 `inputs`, 즉 `Chunk`는 `ChunkOrientedTasklet`을 통해 `ChunkProcessor`의 `process` 메서드 인자로 넘어가게 된다.
이때 `ChunkProcessor`는 `SimpleChunkProcessor` 객체가 초기화 되어 있다. 한번 살펴보자.
public class SimpleChunkProcessor<I, O> implements ChunkProcessor<I>, InitializingBean {
private ItemProcessor<? super I, ? extends O> itemProcessor;
private ItemWriter<? super O> itemWriter;
private final MulticasterBatchListener<I, O> listener = new MulticasterBatchListener<>();
protected final O doProcess(I item) throws Exception {
if (itemProcessor == null) {
@SuppressWarnings("unchecked")
O result = (O) item;
return result;
}
try {
listener.beforeProcess(item);
O result = itemProcessor.process(item);
listener.afterProcess(item, result);
return result;
}
catch (Exception e) {
listener.onProcessError(item, e);
throw e;
}
}
protected final void doWrite(Chunk<O> items) throws Exception {
try {
listener.beforeWrite(items);
writeItems(items);
doAfterWrite(items);
}
catch (Exception e) {
doOnWriteError(e, items);
throw e;
}
}
protected void writeItems(Chunk<O> items) throws Exception {
if (itemWriter != null) {
itemWriter.write(items);
}
}
@Override
public final void process(StepContribution contribution, Chunk<I> inputs) throws Exception {
initializeUserData(inputs);
if (isComplete(inputs)) {
return;
}
Chunk<O> outputs = transform(contribution, inputs);
contribution.incrementFilterCount(getFilterCount(inputs, outputs));
write(contribution, inputs, getAdjustedOutputs(inputs, outputs));
}
protected void write(StepContribution contribution, Chunk<I> inputs, Chunk<O> outputs) throws Exception {
Timer.Sample sample = BatchMetrics.createTimerSample(this.meterRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
doWrite(outputs);
}
catch (Exception e) {
inputs.clear();
status = BatchMetrics.STATUS_FAILURE;
throw e;
}
finally {
stopTimer(sample, contribution.getStepExecution(), "chunk.write", status, "Chunk writing");
}
contribution.incrementWriteCount(outputs.size());
}
protected Chunk<O> transform(StepContribution contribution, Chunk<I> inputs) throws Exception {
Chunk<O> outputs = new Chunk<>();
for (Chunk<I>.ChunkIterator iterator = inputs.iterator(); iterator.hasNext();) {
final I item = iterator.next();
O output;
Timer.Sample sample = BatchMetrics.createTimerSample(this.meterRegistry);
String status = BatchMetrics.STATUS_SUCCESS;
try {
output = doProcess(item);
}
catch (Exception e) {
inputs.clear();
status = BatchMetrics.STATUS_FAILURE;
throw e;
}
finally {
stopTimer(sample, contribution.getStepExecution(), "item.process", status, "Item processing");
}
if (output != null) {
outputs.add(output);
}
else {
iterator.remove();
}
}
return outputs;
}
}
`process` 메서드를 보면, `transform`과 `write` 메서드를 호출하는 것을 볼 수 있다.
`transform`은 `Chunk` 내의 모든 아이템을 루프를 돌며 `doProcess` 메서드를 호출하며, `doProcess` 메서드에서는 `ItemProcessor`를 사용하여 아이템을 변환하게 된다. 또한 `SimpleChunkProvider`의 `doRead`에서 처럼, `MulticasterBatchListener`를 통해 처리 전, 후, 예외 발생 시의 콜백을 실행시키도록 구현되어 있다.
`write`는 `transform`을 통해 변환된 `Chunk`를 한번에 쓰기 작업을 수행하게 된다. 마찬가지로 `MulticasterBatchListener`를 통해 쓰기 전, 후, 예외 발생 시의 콜백을 실행시키도록 구현되어 있다.

방금 다룬 과정은 시퀀스 다이어그램의 파란 배경 부분에 해당한다.
정리
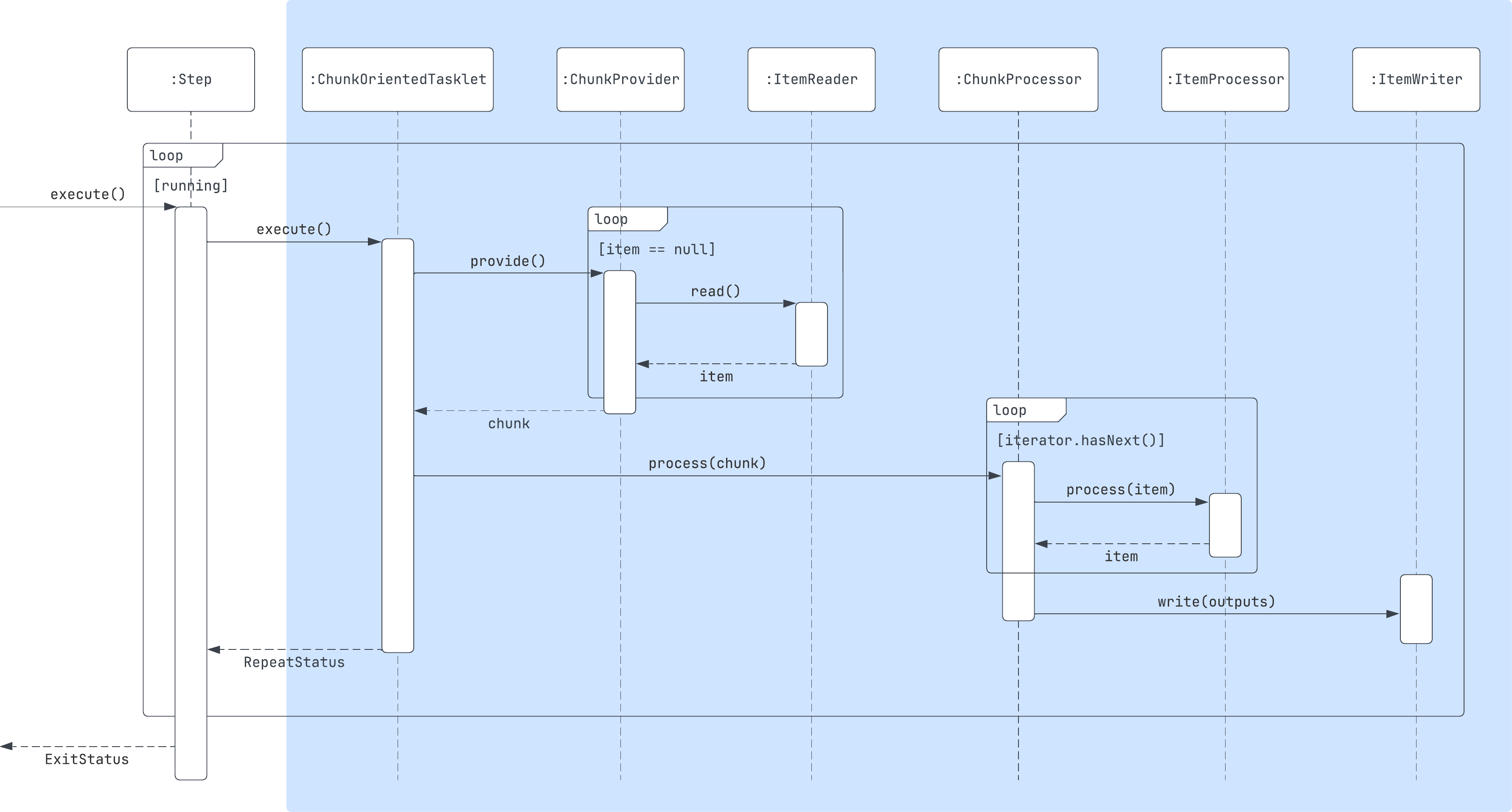
지금까지 `ChunkOrientedTasklet`의 `execute` 함수가 호출되면 일어나는 과정들에 대해서 알아보았다. 간단하게 정리해보자.
`ChunkOrientedTasklet`은 `ChunkProvider`와 `ChunkProcessor`를 통해 청크 기반 배치 작업을 수행한다.
`ChunkProvider`는 `ItemReader`를 사용해 아이템을 읽고 청크를 만든다. `TaskletStep` 처럼 내부 루프에서 `RepeatOperations`를 통해 아이템을 반복해서 읽게 되는데, `SimpleCompletionPolicy`에서 청크 사이즈만큼 아이템을 읽었다면 완료 시그널을 보내 루프를 종료하게 된다.
`ChunkProcessor`는 만들어진 청크를 필요하다면 `ItemProcessor`를 통해 변환하고, `ItemWriter`를 통해 저장하는 역할을 수행한다.
최종적으로 청크를 기준으로 작업이 완료되면, `ChunkOrientedTasklet`에서 청크가 끝이 아닌 경우에는 `RepeatStatus`를 `CONTINUABLE`로 반환하게 되며, 호출부인 `TaskletStep`에서는 `RepeatTemplate`을 통해 다시 `ChunkOrientedTasklet`을 실행시키게 된다.
`ChunkOrientedTasklet`이 다시 호출되면 이전 과정과 동일하게 진행된다.
정리
이번 포스팅에서는 청크 기반 프로세싱이 일어나는 과정에 대해서 상세하게 알아보았다.
`TaskletStep`에서 `ChunkOrientedTasklet`을 실행시키는 과정과, `RepeatOperations`를 통해 반복 수행한다는 점, `TransactionTemplate`을 통해서 청크 단위 작업의 시작과 종료시 트랜잭션 경계를 설정한다는 점들을 알아보았다.
`ChunkOrientedTasklet`에서는 청크 기반 프로세싱이 진행되는 과정을 알아보았다. `SimpleChunkProvider`에서는 `ItemReader`로부터 아이템을 하나씩 읽어온 후 청크 단위만큼 모아 반환하는 것을 볼 수 있었고, `SimpleChunkProcessor`에서는 `ItemProcessor`를 통해 아이템을 하나씩 변환하고, 변환된 아이템이 모인 청크를 `ItemWriter`를 통해 쓰는 것 까지 살펴보았다.
다음 포스팅 부터는 Spring Batch에서 기본적으로 제공하는 대표적인 `ItemReader`, `ItemWriter`, `ItemProcessor` 구현체들을 파일 기반, DB 기반으로 나누어서 살펴볼 것이다.